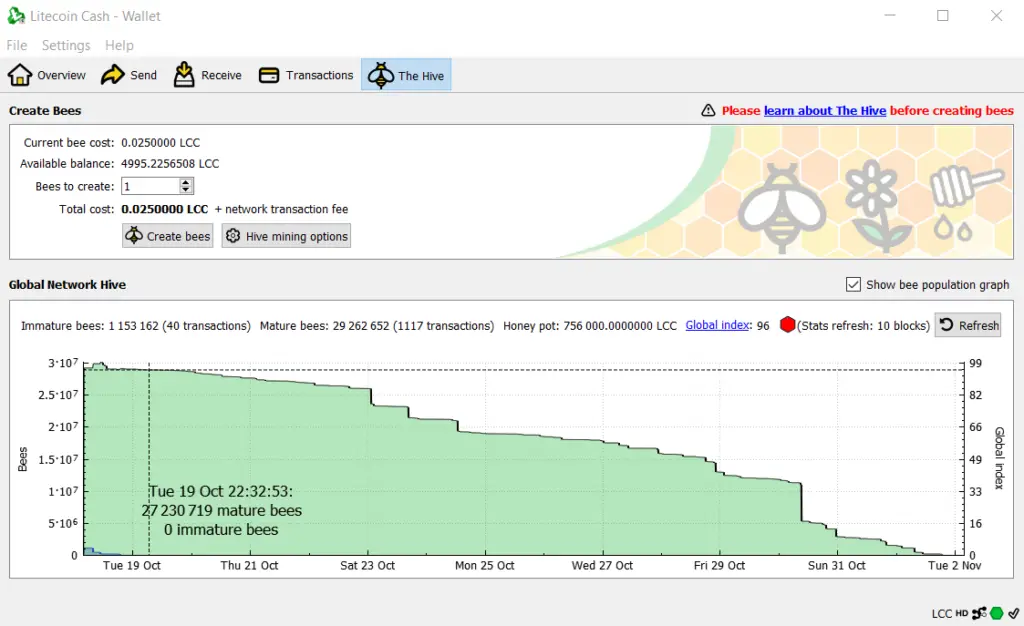
There’s an altcoin I want to get more of. It’s called GoByte (GBX), and is used primarily in Asia. It was created in Malaysia back in 2017 and seems to have fairly active development.
The “major” exchanges available to US citizens — BinanceUS, Bittrex, Coinbase, and Kraken — don’t trade GBX. Of the exchanges that do, HitBTC is not available to US citizens.
However, I did find an exchange that trades in more obscure crypto and is available in the US. It’s STEX. Although they don’t allow funding via ACH, they do allow funding via credit card.
Signing up was easy enough, and no more trouble than any other exchange.
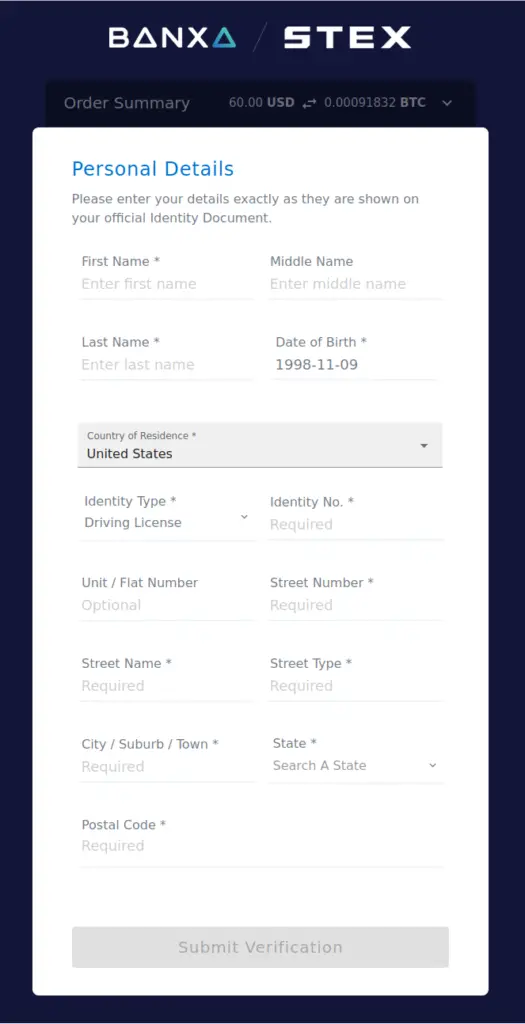
For more trading freedom and lower commissions, you need to verify your identity with them. Their preferred identity verification partner is Cryptonomica, so I started that process after signing up.
Before signing up with Cryptonomica, I did a search for the company. They seemed legitimate and above board.
Cryptonomica is a bit more thorough than other places, in that they wanted both a passport and driver’s license, phone validation, encryption keys with at least 2048 bits, and even a video recording of me stating my identity.
However, when I made it to the phone validation portion, the website threw a Twilio login error. I forwarded this to support, but so far I’ve been unable to finish their verification process.
While this might be an honest glitch caused by someone doing a careless Friday code deploy, it’s worrisome. The feel of the site itself seems a little sketchy, and it was founded by two Ukranians (which isn’t necessarily a bad thing per se). If someone can make a mistake like breaking their 2FA account, who’s to say that they won’t have made other security mistakes that would leak my identity documents to the world?
Cryptonomica didn’t respond to my support email after 24 hours, and attempting to verify the next day failed in the same way. I also noticed that the last post on their Facebook account was in March 2020, so I’m not even sure it’s a going concern. Rather than go through the hassle, I used STEX’s own verification, which was pretty simple and painless, even if it does come with a lesser commission reduction (0.15% vs 0.1%).
While waiting for verification, I tried to create a receiving address for some Tron (TRX) that I wanted to exchange. It wouldn’t let me create a receiving address, saying that verification was required. Since it says that verification takes 36 hours when you start the process, I decided to wait until that finished to try again.
The next day, I got impatient and tried to use one of their other verification partners – Fractal.id. That failed pretty quick when they redirected me to Fractal’s site and their registration page was broken with content security policy script load errors on the developer console. Their other verification partner is only for people in Latvia, Lithuania, and Estonia, so that wasn’t an option.
I go through so much verification nonsense for tax purposes even though I have never failed to report a cent of income and have never lied on my taxes. I really wish the United States would just chip its citizens at birth and any time a financial transaction happens, it’s transmitted to the IRS. That opportunities should be denied to me as a US citizen (such as crypto exchanges in Asia) just because the IRS can’t watch what I’m doing with my money every second is ridiculous. I’m not a fan of being punished because someone else misbehaved.
STEX ended up taking a week to verify my account. This makes sense, since two of their verification partners are broken and their verification team probably has a higher workload. What is odd, though, is that the verification will expire in 6 months, 2022-04-10.
After verification, I was able to transfer in some Tron (TRX), sell it for Bitcoin, and buy some GoByte. The spreads weren’t great, but they also weren’t terrible considering what a low-volume coin GBX is.
I was also able to transfer the coins out of STEX with no difficulty, and now I have a good source for buying GoByte. I’m sure I’ll use STEX again, since I want more GBX.
You can always GBX me at GNyGaHXBUvvUQ8Uv2u5j1o8j3MkkDVGWVx